I 4 programmi in Python: kb_cat.py, kb_cla.py, kb_sta.py kb,_rnd.py in kb_sources.zip
Nota bene: per ridurre di 7 volte il tempo di esecuzione, soprattutto di kb_cat.py, utilizzare pypy (pypy.org) al posto di python.
Download kb_sources.zip
Inoltre è disponibile il programma kb_sim.py che consente di calcolare alcuni indici di somiglianza / similarità fra coppie dei gruppi ottenuti dal precedente programma di catalogazione kb_cat.py.
Per mandarlo in esecuzione:
- digitare in terminale python kb_sim.py
- successivamente digitare il nome del file *_outsrt.txt ottenuto dal programma di catalogazione kb_cat.py
- terminare digitando i nomi dei due gruppi per i quali si vogliono ottenere gli indici di similarità.
Come si può constatare dagli esempi allegati, la coppia dei mammiferi predatori G_03_01 con i mammiferi domestici G_03_00 ha indici di similarità di valore ben maggiore rispetto alle altre coppie.
Utilizzando il programma kb_sim_all.py, ogni gruppo è confrontato con tutti gli altri determinando quanti valori siano identici nelle variabili deile coppie in esame. Minori sono le coincidenze dei valori delle variabili presenti in entrambi i gruppi e maggiormente distinti fra di loro sono i gruppi.
I risultati del programma kb_sim_all.py possono confermare il valore di KIndex ottenuto dal programma kb_cat.py.
Download kb_sim.zip
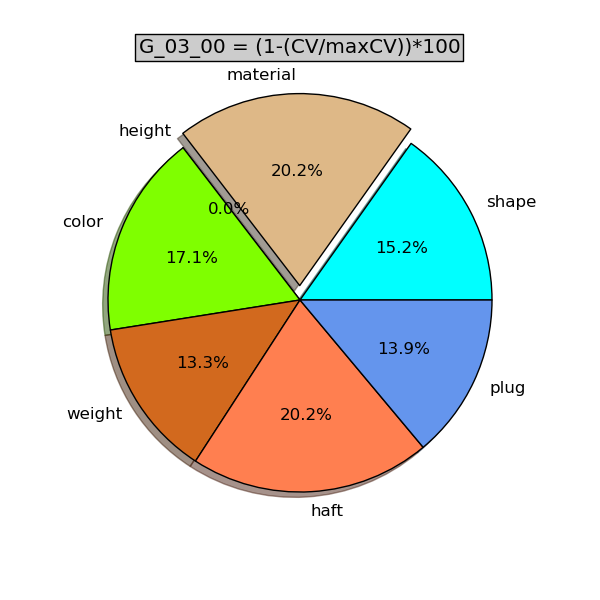
Inoltre è disponibile il programma kb_pie.py che consente di ottenere un grafico a torta dei CV delle variabili / colonne del gruppo scelto.
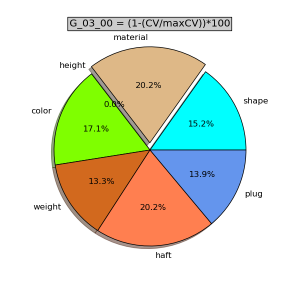 Per mandarlo in esecuzione:
Per mandarlo in esecuzione:
- digitare in terminale python kb_pie.py
- successivamente digitare il nome del file *_cv.txt ottenuto dal programma di catalogazione kb_cat.py
- terminare digitando il nome del gruppo per il quale si vuole ottenere il grafico a torta dei CV.
Download kb_pie.zip
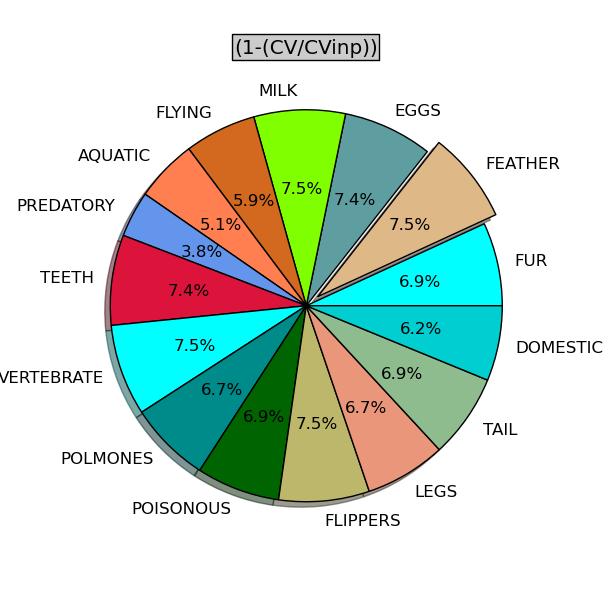
Inoltre è disponibile il programma kb_pie_cv.py che consente di ottenere un grafico a torta delle variabili / colonne evidenziandone il contributo a caratterizzare i gruppi attraverso il rapporto fra i CV dopo la catalogazione e i CV prima della catalogazione.
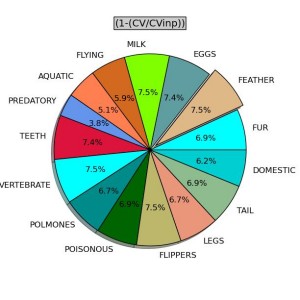 Per mandarlo in esecuzione:
Per mandarlo in esecuzione:
- digitare in terminale python kb_pie_cv.py
- successivamente digitare il nome del file *_cv.txt ottenuto dal programma di catalogazione kb_cat.py
Download kb_py_cv.zip
Contact us
Visite:
(1471)